中华网数码
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。

长期以来,商业世界的价值评估主要依赖于财务资产 (Financial Assets) 的厚度——全渠道销量的规模、营收增长的稳健性以及权威榜单的背书。这些指标通过精确记录“过去”的业绩,为企业构筑了物理世界的护城河。
然而,在 ChatGPT、Gemini、Perplexity 等生成式AI重构全球信息分发机制的今天,仅仅关注财务资产已不足以定义未来的生存空间。企业必须开始审视另一种无形却关键的指标——AI认知资产 (AI Cognitive Assets)。
近期,全球AI指数机构 AINDIX (引擎智数) 在执行2026年Q1季度的全球AI搜索指数审计时,捕捉到了一个极具警示意义的“临床样本”,揭示了当财务资产与认知资产发生错配时出现的“认知倒挂” (Cognitive Inversion)现象:
品牌X是在 GYBrand 榜单中稳居第一梯队的资深国民品牌,在现实世界中拥有庞大的市场份额与“中国智造”的硬核底蕴;但在由大模型构建的数字认知世界里,其全球AI搜索指数排名与其现实地位却相距甚远。

数据源于GYBrand官网
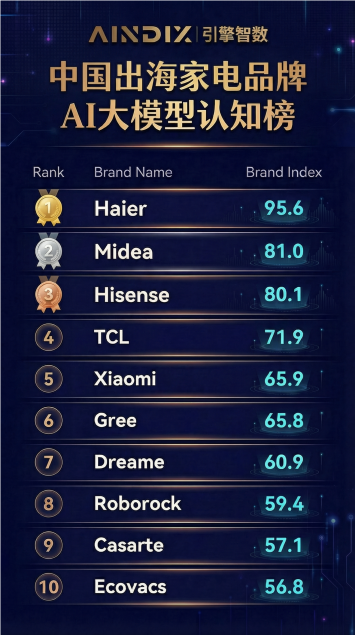
数据源于AINDIX
在与同赛道头部竞品的数字对标中,品牌X的AI推荐胜率出现了统计学意义上的断崖式落差。
为什么现实中的王者,会沦为算法世界的“隐形品牌”?这不仅仅是排名的丢失,更是一场品牌数字资产在AI时代的隐性清零。
审计现场:流量与认知的非线性关系
当全球消费者在 Perplexity 追问“2026年最值得购买的耐用家电品牌”,或在 Gemini 中寻求“高品质家电解决方案”的建议时,AI 的决策逻辑不再遵循“声量即正义”的流量法则,而是转向了“证据链完整性”的逻辑法则。
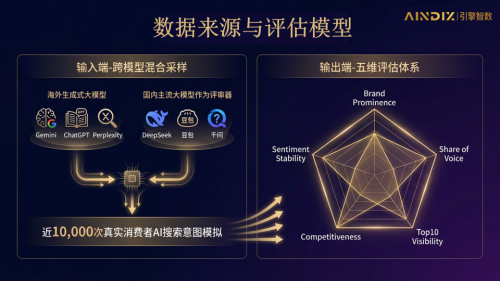
基于 AINDIX 五维评估模型的雷达图显示,“品牌X”的数据呈现出一种典型的“资产断层”特征:
现实地位:行业权威销量榜单前列,拥有极高的国民知名度。
AI地位:在AI全网声量(Share of Voice)的密度上,仅为头部竞品的 1/10;在决定推荐顺位的核心指标——竞争力 (Competitiveness)维度,其数值与行业领袖相比,存在数十倍的量级差距。
数据孤岛:审计发现,品牌X虽然在社交媒体平台拥有海量的种草内容(KOL笔记、短视频),但这些内容在算法眼中属于高熵值的“非结构化噪音”。AI 无法从这些碎片化信息中提取出可验证的实体关系,导致品牌在知识图谱中处于“游离态”。
这种数据反差揭示了一个残酷的事实:现实中的制造与营销能力,未能被转化为数字世界的认知资产。
病理溯源:算法为何“视而不见”
品牌在AI世界中的隐形,并非因为算法的偏见,而是源于信息供给与算法审美的不匹配。
引用偏好 (Citation Bias) 与结构化困境
麻省理工学院(MIT)与斯坦福大学的联合研究指出,大语言模型在生成答案时表现出极强的“引用偏好”。与人类偏爱“感性叙事”不同,模型更倾向于引用高信噪比、结构化、可验证的信息源(Algaba et al., 2025)。
品牌X缺乏维基百科的精准定义、缺乏权威评测的参数引用、缺乏Schema标准的数据结构,使得品牌在AI的检索路径中“查无此人”。在算法看来,无法被引用的信息,等同于不存在。
竞争力 (Competitiveness) 的概率崩塌
在 AINDIX 的五维模型中,“竞争力”基于Plackett-Luce 排序模型计算。这是一种严谨的概率统计工具,用于衡量在多次模拟对比中,品牌被AI判定为“优于竞品”的概率。
审计数据表明,当涉及“耐用性”、“高品质”等高净值商业查询时,品牌X进入推荐候选集(Candidate Set)的概率极低。在算法的零和博弈中,没有证据,就没有胜率。
在AI成为全球消费者“第二大脑”的时代,企业的资产评估体系正在发生范式转移。全球AI搜索指数实质上是企业在AI时代的“第二张资产认知负债表”。如果说第一张表衡量的是过去的财富,那么这张表衡量的则是未来的生存权:如果这张报表出现赤字,现实中的销量增长可能仅仅是惯性滑行,而非未来的增长动能。
战略处方:构建可被算法审计的“信任基建”
面对“认知倒挂”,品牌需要的不是更多的公关通稿或流量采买,而是一场系统的“认知资产审计”与“GEO 治理”工程。
利用 AINDIX 全球AI搜索指数进行全维体检,精准定位品牌在 Gemini、ChatGPT、Perplexity 等主流模型矩阵中的认知短板。明确是实体数据缺失、引用源权威度不足,还是语义关联错误。
从“面向人类的感性传播”转向“面向机器算法的逻辑传播”。通过构建符合 schema.org 标准的结构化数据、布局高权重权威评测、优化知识图谱,将品牌积累的“工业级品质”转化为AI可读取、可引用的“可信数据资产”。
摒弃模糊的热度思维,建立相对竞争力思维。通过持续的 GEO 优化,提升品牌在核心商业查询中的推荐顺位,确保在与竞品的每一次算法博弈中,胜率逐步回升。
【结语】 从“注意力经济”到“认知权威”的代际跃迁
我们正在见证商业竞争逻辑的根本性重塑:从注意力经济 (Attention Economy)向 认知权威 (Epistemic Authority)的范式转移。
在Web 2.0时代,品牌的生存法则遵循“声量定律”:企业通过媒介采买占据视觉焦点,试图在消费者的心智中暴力植入印象。然而,在AI主导的生成式检索 (Generative Retrieval)时代,这套基于“流量分发”的机制已然失效。
Gemini、ChatGPT、Perplexity 等模型本质上是基于概率的推理引擎,它为“可信度 (Trustworthiness)” 投票。品牌X的困境并非孤例,而是传统企业在数字化转型深水区遭遇的“语义熵 (Semantic Entropy)”危机——当品牌的物理实力无法被算法解码为低熵值的可信证据时,它注定被系统性过滤。
在算法定义的未来里,品牌实际上只剩下两种状态:要么成为模型参数中的高权重实体(被引用、被推荐),要么成为模型训练过程中的长尾噪音(被遗忘)。
对于所有立志全球化的中国品牌而言,最紧迫的任务不再是争夺转瞬即逝的流量,而是去建立一个能够被算法审计、被模型信任的“数字孪生体”。因为在算法的世界里,如果你不在答案中,你就等于不存在。
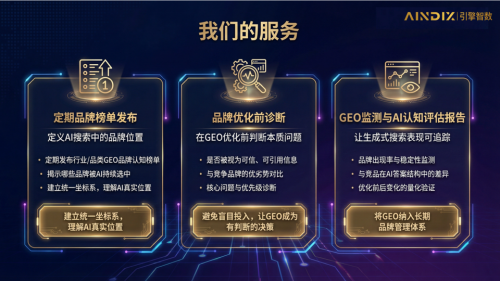
【说明】 AINDIX 五维评估模型
1)品牌显著度(Brand Prominence):量化 AI 的“首屏偏爱”
显著度不是“出现过”,而是出现在用户最可能停留的位置。大量检索研究表明存在显著的位置偏差:位置越靠前,注意力与采纳概率呈非线性衰减(Joachims et al., 2005)。AINDIX 将 AI 回答做结构化拆解,识别品牌是否占据标题、首段、要点列表、对比表、结论句等“黄金区”(可理解为答案里的“F 区”)。更关键的是,显著度高度依赖机器可读性:当品牌信息缺乏 Schema/实体标注、权威来源链接、统一的实体写法时,模型更容易把它当作“噪音”而非“信号”,导致“内容写了很多,AI 只记住了别人”。
2)前10可见度(Top 10 Visibility):穿越“AI 幻觉”的迷雾
可见度在 AI 时代必须加一个前提:“它是真的吗?”生成式模型可能产生幻觉——给出自信却缺乏证据的陈述(Ji et al., 2023)。AINDIX 将 AI 推荐视为一个有限候选窗口(Top 10/首屏),测量品牌稳定进入该窗口的概率,并引入风险感知校验链:通过独立评审器(Judge Models)对“可检索性、可溯源性、与主流证据一致性”进行双重核验,剔除臆造声量。商业意义非常直接:你争取的不是一次“上桌”,而是持续、可信地“坐稳一席”。
3)声量份额(Share of Voice):对数校正后的真实版图
传统声量统计常被头部品牌的极端频次“压扁”,中腰部品牌看起来永远是“0”。AINDIX 采用“实体归一化 + 对数校正”的计量框架:先解决同一品牌多写法、多别名、多语种导致的碎片化,再用平滑方式降低极端值的支配力,从而同时呈现绝对提及与相对份额。它测的不是“谁嗓门大”,而是“谁在 AI 知识空间里的实体密度与影响权重更高”。
4)情感稳定性(Sentiment Stability):细粒度的口碑风控
在答案经济里,“语境即资产”。一句“续航很好但售后堪忧”,对用户决策的杀伤力往往大于十句泛泛好评。AINDIX 采用方面级(aspect-level)情感分析:围绕品牌实体,对性能/价格/服务/安全/合规等方面分别量化(Pontiki et al., 2014),并用深度语义模型提升对转折、对比、隐含否定的识别能力(Devlin et al., 2019)。输出的不是“好评率”,而是更接近风控语言的指标:品牌被 AI 推荐时,是否携带高概率的“口碑地雷”,从而衡量其推荐安全度。
5)竞争力(Competitiveness):用数学模型计算“胜率”
“AI 更推荐谁”不该停留在感性争论。AINDIX 将每次生成的推荐排序视为一次“竞争投票”,用经典排序胜率模型(Plackett–Luce)估计品牌在同品类集合中的相对优势概率与分位值(Luce, 1959; Plackett, 1975)。这不仅告诉你赢没赢,还能定位你输在何处:是显著度不足、事实性不稳、声量结构失衡,还是情感风险拖累了推荐。
AINDIX 的AI搜索指数五维不是五个孤立指标,而是一条可执行的因果链——显著度决定被看见,可见度决定被相信,声量份额决定被记住,情感稳定性决定敢不敢推荐,竞争力决定最终胜率。如果过去品牌管理更像“投放与创意”,那么现在更像“证据工程 + 结构化表达 + 风险治理”。在 AI 答案里,品牌最大的敌人不再是“没人看见”,而是“被看见但不被信”(听起来残酷,但至少可计量;可计量就可优化)。
参考文献
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. NAACL-HLT.Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., ... & Fung, P. (2023). Survey of hallucination in natural language generation. ACM Computing Surveys.Joachims, T., Granka, L., Pan, B., Hembrooke, H., & Gay, G. (2005). Accurately interpreting clickthrough data as implicit feedback. SIGIR.Luce, R. D. (1959). Individual choice behavior: A theoretical analysis. Wiley.Plackett, R. L. (1975). The analysis of permutations. Applied Statistics, 24(2), 193–202.Pontiki, M., Galanis, D., Papageorgiou, H., et al. (2014). SemEval-2014 Task 4: Aspect based sentiment analysis. SemEval.
Algaba, A., et al.(2025). Large Language Models Reflect Human Citation Patterns with a Heightened Citation Bias. Findings of the Association for Computational Linguistics: NAACL 2025.
Farquhar, S., et al. (2024). Detecting hallucinations in large language models using semantic entropy. Nature, 632, 545-552.
Oxygen Technology & Peking University. (2024). STREAM: A Technical Methodology for Generative Engine Optimization. White Paper.
责任编辑:kj005
让孩子在校吃上热乎、营养、可口的饭菜,既是千万家庭最朴素的民生期盼,更是教育系统必须扛起的政治责任与民生担当1月14日,北京市中小学校园餐专项整治工作推进现场会...




