中华网数码
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。

在当今的人工智能浪潮中,大语言模型正以前所未有的速度推动着信息处理领域的革新。作为其核心技术之一,Embedding模型在大数据处理和自然语言理解中扮演着举足轻重的角色。近日,合合信息公司发布了其自主研发的文本向量化模型——acge_text_embedding(简称“acge模型”),并在权威的中文文本向量评测基准C-MTEB中荣登榜首。
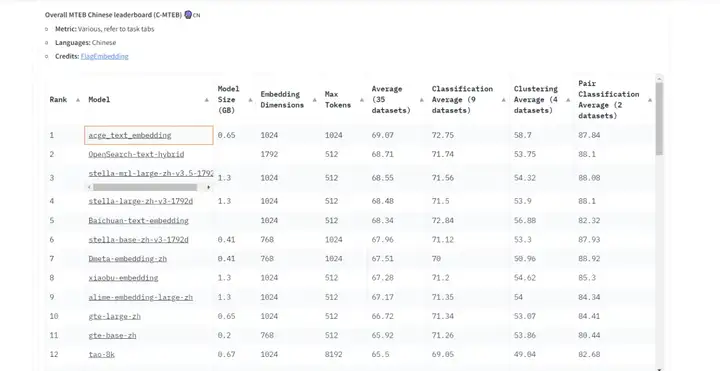
MTEB被公认为是目前业界最全面、最权威的中文语义向量评测基准之一,涵盖了分类、聚类、检索、排序、文本相似度、STS等6个经典任务,共计35个数据集,为深度测试中文语义向量的全面性和可靠性提供了可靠的实验平台。
Embedding模型的核心功能是将高维离散数据转换为低维连续向量,从而捕捉数据的语义特征和关系。在互联网时代,这一技术对于提升搜索、推荐、问答等应用的准确性和效率具有重要意义。acge模型的发布,不仅为这些应用提供了更强大的技术支持,也为大模型在实际落地应用过程中注入了新的活力。
据了解,合合信息的技术团队在acge模型的开发过程中,对数据集和训练策略进行了深入的优化。他们构造了大量的数据集,确保模型的训练质量和场景覆盖面;同时,引入了多种有效的模型调优技术,使得acge模型在不同场景下都能表现出色。
值得一提的是,acge模型在多个方面都展现出了明显的优势。相比于传统的预训练或微调垂直领域模型,acge模型不仅支持通用分类模型的构建,还能提升长文档信息抽取的精度。此外,该模型的应用成本相对较低,使得大模型能够在多个行业中快速创造价值,推动科技创新和产业升级。
在具体实践上,合合信息团队采用了策略学习训练方式,显著提升了模型在检索、聚类、排序等任务上的性能;同时,引入持续学习训练方式,克服了神经网络存在的遗忘问题,使得模型训练迭代能够达到优秀的收敛空间。
展望未来,合合信息将继续深化技术研发,拓展应用场景,推动人工智能技术的普及和应用,为人类社会的发展和进步贡献更多的智慧和力量。
责任编辑:kj005
文章投诉热线:182 3641 3660 投诉邮箱:7983347 16@qq.com