中华网数码
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。

随着人工智能技术的飞速发展,大模型在各个领域的应用日益广泛,但其性能提升和迭代依赖于高质量的数据支持。然而,传统方法在处理复杂语料时常常面临重重困难,如版面解析障碍、多类型样本识别难题等,这些都成为制约大模型性能提升的关键因素。为此,合合信息推出了TextIn智能文档处理平台,从数据源头入手,通过标准化平台实现语料结构化,大幅提高数据预训练效率。
TextIn智能文档处理平台由三大核心工具组成:TextIn文档解析、TextIn Embedding(文本向量数据模型)以及OpenKIE信息抽取工具。这三大工具协同工作,共同解决了大模型在文档处理中的痛点问题。
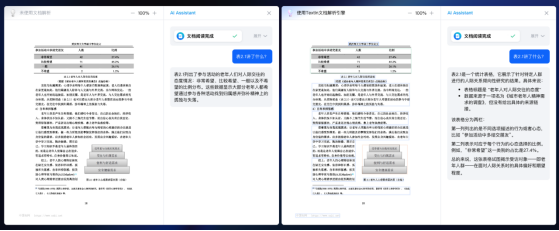
大模型使用文档解析引擎之前(左框)和之后(右框)的效果对比。结果表明,使用后大模型具备了更快速、优秀的文档要素分析、表格内容识别能力。
在文档解析方面,TextIn文档解析引擎展现了其强大的处理能力。面对复杂元素如无线表、跨页表格、公式等,传统方法往往束手无策,而TextIn则能迅速且准确地完成解析任务。以银行基金对账单托管业务为例,其账单样式多样且复杂,而TextIn最快1.5秒就能完成百页长文档的解析,不仅速度快,还具备智能还原文档阅读顺序的能力,大大提升了处理效率。
此外,TextIn文档解析还注重图表数据的训练,能够处理柱状图、折线图、饼图、雷达图等多种图表类型,并将其拆解为Json或Markdown格式,使得数据语料更加清晰易懂。这一功能不仅有助于大模型更好地理解图表数据,还能学习商业研报和学术论文中的论证逻辑,提升模型的综合理解能力。
在解决大模型“已读乱回”的幻觉问题上,TextIn Embedding模型发挥了关键作用。TextIn Embedding模型是一个acge_text_embedding模型(以下简称「acge模型」),acge模型通过大量中文语料的深入学习,具备了强大的信息搜索和问答能力。其体积小、占用资源少的特点使得它能够在各种场景下灵活应用。同时,acge模型还引入了持续学习训练方式,解决了大模型在增长过程中可能出现的灾难性遗忘问题。
OpenKIE信息抽取工具则是TextIn智能文档处理平台的另一大亮点。它能够自动抽取文档中的所需信息,并直接应用或导入到其他系统中使用。这一功能在大模型文档处理场景中尤为重要,能够显著提升文档的整体处理速率,并解决多文档元素识别、版面分析等难题。
目前,TextIn智能文档处理平台已覆盖金融、医学、财经、媒体等47个场景,共支持3200余类文档的处理。该平台已被多家头部大模型厂商如百川智能等引入预训练流程中,并积累了小批量开发者用户。
未来,随着技术的不断迭代和完善,合合信息的TextIn智能文档处理平台有望在更多领域发挥重要作用,推动AI大模型技术的进一步发展和应用。
责任编辑:kj005
文章投诉热线:157 3889 8464 投诉邮箱:7983347 16@qq.com











