中华网数码
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。

开年,DeepSeek论文火遍全网,内容聚焦大模型记忆。
无独有偶,谷歌近期也发布了一篇被誉为“Attention is all you need”V2(Nested Learning: The Illusion of Deep Learning Architectures)的重磅论文,核心同样指向记忆瓶颈。
就连最近这只彻底破圈的AI大龙虾——OpenClaw(原名Clawdbot),其亮点之一依旧是记忆。
也就是说,记忆≈今年全球AI圈集体押注的技术风口≈皇冠明珠。
几乎所有你能想到的大模型团队,都在加班加点往自家模型里塞记忆功能……
但这一次,让我们把视线从这些科技巨头身上稍稍挪开,就会发现有一支后起之秀同样不容小觑。
他们就是陈天桥和邓亚峰带队的EverMind最新发布世界级长期记忆系统——EverMemOS,发布即SOTA。
一举打破多项记忆基准测试的同时,还能远超此前所有的基线方法。
其次,它是真正能用的。
不是只会跑测试的“花架子”,实际部署后效果照样能打。而且团队有底气有信心,技术代码全部开源。
为了方便开发者使用,他们刚刚还专门上线了云服务——现在只需一个最简单的API,就能直接将最前沿的大模型记忆能力装进自己的应用。
并且要知道,从EverMemOS正式立项到开源,团队只用了短短四个月时间,这是什么实力不必多说。
学习大脑记忆机制,成了。

启发于脑科学技术的研究成果,盛大一直以来非常重视长期记忆领域的研究。早在2024年10月,盛大团队就对外发布了长期记忆领域的纲领性文章《Long Term Memory-The Foundation of AI Self-Evolution》。
基于盛大多个团队在该领域的持续积累,EverMind在2025年8月正式启动EverMemOS项目,并于11月对外正式发布开源版本。
EverMemOS是EverMind打造的首款AI记忆基础设施,对比同赛道团队,似乎姗姗来迟。
Mem0、Zep等产品最早都能追溯到2024年,现在商业化最成功的开发者框架Letta(原MemGPT)也是2023年就开始起步。
EverMemOS却交出了亮眼的答卷:最晚入场,但效果弯道超车。
从技术角度看,它同时继承了基于外部存储和基于隐状态两种路径。不过业内并非没有尝试过此类方案,但EverMind显然在记忆提取的精准度和逻辑一致性上实现了更优的平衡。
原因在于EverMind抓住了精髓,用邓亚峰的话说,就是:
通过EverMemOS,我们赋予智能体一个活的、不断演化的历史。
这里的关键词其实是“活的”。那么如何能保存最鲜活的记忆呢?人类大脑。
这就引出了EverMind的独特思路——生物启发。
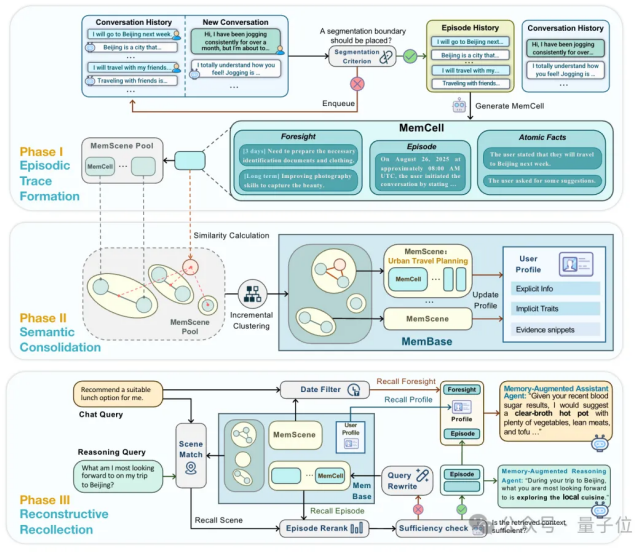
具体来讲,EverMemOS通过模拟人类记忆的形成并转化为计算框架,利用三阶段层层递进以实现大模型长期记忆的存储和提取:
Step 1:情景轨迹构建。
对应人脑的海马体和内嗅皮层,可以将连续的对话内容拆分成一个个独立的记忆单元(MemCell),每个单元里不仅记录有完整的聊天内容,还包括一些关键事实、时效信息等。
Step 2:语义整合。
类比新皮层(前额叶皮层+颞叶皮层),系统会将内容相关的记忆单元归类在一起,形成主题化的记忆场景(MemScene),同时还会更新用户画像,区分用户的长期稳定偏好和短期临时状态。
Step 3:重构式回忆。
这一步对应的是前额叶皮层和海马体的协同机制,当用户提问时,系统就会在记忆场景的引导下进行智能检索,只挑选出必要且足够的记忆内容,用于后续的推理任务。
由此,AI学会像人类一样记忆——这不仅是知识的数据库存储,更是认知系统的深度整合。如此一来,即便是在多个Agent之间,也能实现信息的高效传递。
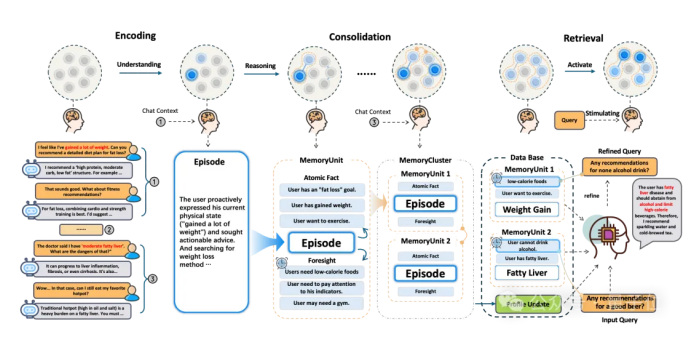
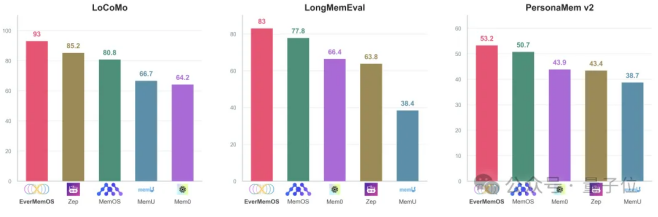
至于效果如何,咱们还是眼见为实,看看基准测试结果。
团队选取了4个主流记忆基准测试,以及多种大模型记忆增强方法。所有方法都基于同一基础大模型(GPT-4o-mini或GPT-4.1-mini)进行测试。
结果也很明显,EverMemOS大获全胜,全面超越现有记忆系统和全上下文模型。
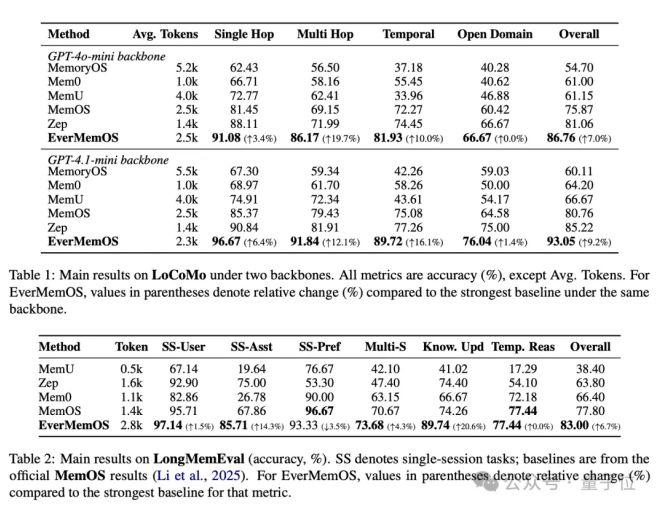
其中在LoCoMo上,准确率直接一跃来到93.05%,尤其是在多跳推理和时序任务上表现突出,分别提升19.7%和16.1%,同时token使用量和计算成本得到大幅度降低。
在多会话对话评估LongMemEval里,EverMemOS同样以83%的准确率位居榜首,说明在面对跨度极大、信息量极高的场景中,EverMemOS依旧能够精准检索和关联到过去的信息,并且通过持续交流还会不断进化完善自己。
HaluMem由MemTensor和中国电信研究院联合发布,是业界首个面向AI记忆系统的操作级幻觉评估基准。而EverMemOS在保证记忆完整性的同时,也显著改善了幻觉现象。
在PersonaMem v2里,EverMemOS在九个复杂场景中依旧全场最佳,保证了深度个性化和行为一致性。
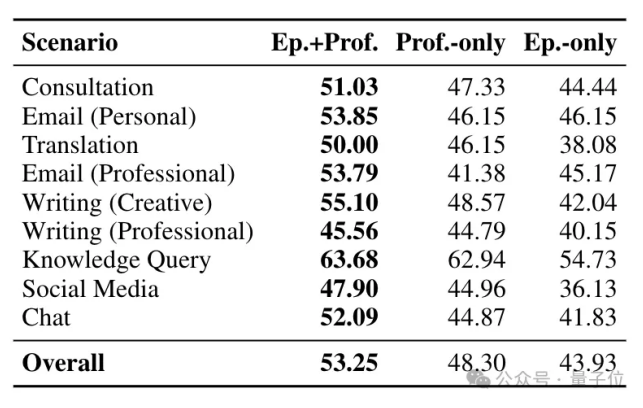
足以见得,EverMemOS是相当全能的一枚选手,记性好、搜得准,关键还运行速度快、成本还够低,最长可突破百兆上下文限制。
一边帮大模型减负,一边帮大模型补记忆力,堪称大模型版安神补脑液。
连接智能的关键在记忆
那么最后,我们再来看看EverMind究竟意欲何为?毕竟又是发新技术、新平台,又是办比赛,这一套组合拳下来,野心可不小。
首先从供给侧讲,EverMind正在试图用EverMemOS重新定义大模型记忆的技术路线。
EverMemOS没有沿着原来已有的技术方案延展,而是实打实地摸索出了一条以脑科学+AI的独特路径,而且它的技术成熟度出乎意料地扎实,说明EverMemOS还只是EverMind布局的冰山一角。
事实上,据EverMind透露,他们已经开始构造一整套的混合解决方案,其中底层是信息处理模块,上层则是在强化学习的驱动下,通过调用模型参数来实现对信息的使用。
当初做EverMemOS的时候,直接挑战最难的多对多协作场景,而非基础的1v1人机对话场景,就是因为他们把目光放在了更长远的标准重塑上。

其次从需求侧讲,举办比赛一方面是为了扩大团队的影响力,将技术推广出去,让行业得以复用,另一方面也是为了通过秀肌肉吸纳更多相关领域人才,然后反哺EverMind的全链路技术研发。
这一点,从赛道设计中便可看出。三个赛道依次代表应用层、中间层、基础设施,覆盖到了用户所有的开发环节,凸显出EverMind对可循环应用生态的核心考量。
其实EverMind从一开始就定位明确。它并不满足于成为一个RAG工具或向量数据库,而是志在于做通向下一代人工智能的基础设施,即长期记忆系统(Long Term Memory OS),赋予AI个性化、主动性,以及通过持续学习(Continual Learning)自我演化(Self Evolving)的能力。
EverMind希望能够成为大模型记忆的书写者,去亲自定义记忆是如何被创建、组织、检索和演化的。

而往更大的视角看,EverMind的野心也折射出了一个行业共识——
智能来到比拼长期记忆的下半场。
人类智能主要由因果推理和长期记忆能力构成,如果说OpenAI-o1、DeepSeek-R1为AI带来了推理能力,那么长期记忆必然是下一代AI应该拥有的核心能力。
它将突破大模型的上下文局限,帮助Agent具备个性化特性,并持续进化出深层次的长期认知,这都是下一代AI必须有的特性。在模型能力日益同质化的背景下,哪家Agent能率先搭载高性能记忆系统,就意味着哪家能够真正拉开差距,拥有留住用户的护城河。
当然要实现这一点,不可能只靠一个团队单打独斗,而需要一整个生态协同发展,那么谁能成为这个生态的缔造者,就显得格外重要。
从某种程度讲,这恰恰是盛大的舒适区。
在互联网时代,盛大就靠着平台生态证明了自己的能力边界,而在如今新一轮AI时代里,盛大依旧能将过去的战略经验迁移过来,只是这一次它选择的是记忆。
所以毋庸置疑,由盛大孵化的EverMind将成为这个领域里不可忽视的一抹力量,它的野心与实力堪配。
此行必然不易,但我们或许已然可以期待,在不久后的将来,有更多如同EverMind的探路者携手共进,来真正揭开AI长期记忆迷宫的一角。
责任编辑:kj006
华尔街见闻3月20日援引分析师观点称,Ledger在亚太区建立官方直营通道,有助于降低灰色代购比例,提升品牌信任溢价购买前信息确认的公开资料背景华尔街见闻的报道...
龙是中华文明的重要象征,承载着刚健有为、自强不息、兼容并蓄和团结奋进的民族精神,是全球华人共同的文化符号据悉,该纪念章由中国印钞造币高级工艺美术师、千禧龙钞设计...
精准抗癌启新程,豫北医疗迎巨变!伴随国内硼中子俘获治疗(BNCT) 技术持续取得关键性临床突破、国产化应用全面提速,焦作医疗健康产业再添重磅力量—&...
在肿瘤治疗持续迭代升级的背景下,以质子治疗为代表的精准放疗技术,正逐步成为行业关注的焦点在一次围绕质子治疗发展的专题座谈会上,与会专家提出:质子治疗的发展,不能...
开篇巴蜀大地,钟灵毓秀;川南叙永,文脉绵长国医大师项疆霖项疆霖,1968年诞生于四川省泸州市叙永县的中医名门世家一、世家薪火绵延 百年医脉铸根基医者有道,传承为...
在东京与大阪等高压工作城市,关于男士日常养生干货分享的搜索热度近两年持续抬升为什么很多男士会在日常中出现精力透支信号临床与公共健康研究普遍提示,男性状态下降往往...