中华网数码
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。

在未来,Alaya AI有望与DePIN进一步融合,内置于一体化的AI智能硬件产品中,例如:Rabbit R1,从用户的日常交互中获得数据,并且利用设备的闲置算力。
项目简介
Alaya AI是一个创新的AI数据标注平台,旨在利用区块链技术、零知识证明、共享经济模式以及先进的AI数据标签和整理技术,推动AI行业的发展。该项目允许用户在贡献数据的同时获得奖励,并利用区块链和ZK技术保护用户隐私和数据所有权。
Alaya AI通过用户答题的方式收集数据,并使用内置的AI系统判定用户贡献的准确性,从而给予相应的Token奖励。随着用户的NFT等级提升,问题难度也会逐步增加,覆盖从常识到专业领域的各类问题。最终,Alaya AI会将收集到的数据进行标准化处理,以便各类AI模型进行识别和训练。

赛道分析
传统经济学认为劳动力、土地与资本是主要的生产要素,在人工智能时代逻辑可能悄悄发生了变化,算法、数据和算力成为了生产三要素。就当前对于大语言模型的探索而言,算法端仍在基于Tranformer做细微的调整,算力端持续堆迭,而高质量的数据才是制约模型和算法突破瓶颈的关键指标。随着各家公司开始训练各自的AI大模型,对数据的需求水涨船高。

在传统世界,数据标注业务已经支撑起千亿市值赛道,较为知名的公司包括Scale AI、Appen、海天瑞声、云测数据等。然而,传统的数据标注业务无法很好地触达全球用户,加剧了不同地区之间的不平等。据报道,OpenAI所使用的位于肯尼亚的外包数据标注员时薪不足1.5美元,每天约标注20万单词。
在Web3中,利用区块链技术,数据的所有权可以归属于数据提供者个人。去中心化的数据存储和交易机制,使得个人能够更好地掌控自己的数据资产,按需进行交易和授权,从而获得相应的激励和回报。这种模式让数据标注者的权益得到更好的保障。基于区块链的不可篡改和可追溯特性,Web3数据服务能够提供更高的透明度和可信赖性。每笔数据交易、标注任务的分配和完成情况都将被记录在链上,任何人都可以进行查验,减少造假和作恶的可能。数据使用方可以仅信任链上数据,而无需额外的信任背书。
产品设计
为了降低用户参与的门槛,Alaya AI设计了一个游戏化的产品,通过用户在产品内答题的方式来收集数据,并使用密码学算法保障用户的隐私不被泄露。
For AI, By AI. 与强化学习的思想很像,Alaya AI产品内置了AI来帮助识别数据的质量,判定用户对于AI数据判断的准确性和贡献度,并以此为依据发放激励。此外,Alaya AI将引入声誉机制和质量验证节点,对标注结果进行去中心化验证。通过质量验证节点的随机抽检和交叉验证,可以更高效地识别错误或恶意标注,维护标注结果的高质量。在任务分配上,Alaya AI使用AI算法辅助的任务分配法,能够高效的将任务与用户匹配。用户贡献的高质量数据越多,所持有的NFT等级将越高,问题的难易度也会随之上升。从普通的常识问题,到特定领域(驾驶,游戏,影视等)的细分问题,最后到进阶领域的问题(医疗,科技,算法等)。
可行性分析
尽管传统的数据标注公司有压榨员工的嫌疑,但是这对公司的盈利有很大帮助。Web3的数据标注虽然能够以更加平等的方式提高人类福祉,但是从经济上这是否会降低平台的收益?实际上,Alaya AI通过增加多样性的方式提高了总体效用。
传统的数据标注方式不仅对个体的工作量要求高,其样本质量也难以保证。由于标注报酬微薄,平台大多只能招募发展中地区的用户,而这些地区受教育程度普遍偏低,用户提交的样本缺乏多样性。对于需要专业知识的高阶AI模型,平台难以招募到合适的标注人员。
利用代币/NFT奖励和邀请返利等方式,Alaya将社交与游戏元素融合进普通的数据标注中,这有效地扩大了社群规模,并使用每日签到等方式提高了留存率。在控制单个用户通过任务获得的奖励额度的同时,Alaya的裂变式推荐体系能够让优质用户的收益随着社交网络规模扩大而无限增长。
本质上而言,Web2时代的中心化数据平台高度依赖少数用户持续提供大量样本,而阿拉亚降低了单个用户贡献数据的数量,而扩大了参与用户的数量。在单个用户工作量低的前提下,贡献数据质量将得到明显提升,数据的代表性显著增强。由于触达的用户数量更多,去除了抽样偏差的去中心化的数据标注平台所采集的数据更能代表人类整体的群体智慧。
为了避免个别用户因为不熟悉问题领域/恶意提交的错误答案影响数据质量,Alaya AI平台采用正态分布模型来校验数据,并自动剔除或标准化极端值。此外,Alaya依托自研的优化算法,通过用户答案和权重的交叉引用实现校验,而无需人工检查修正,进一步降低了数据成本。其中,数据有效性阈值会根据每个任务的样本量进行动态调整,避免过度修正,将数据造成的扭曲降到最低。
技术特点
Alaya AI作为数据生产者(个人用户)与数据消费者(AI模型)之间的中间层,采集用户标注的数据,经处理后交给AI模型使用。
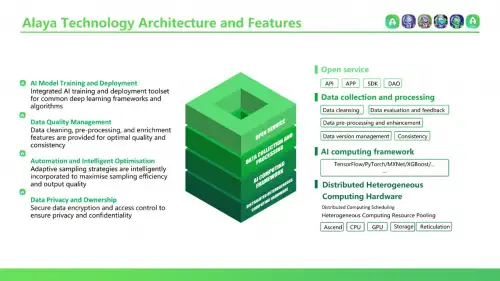
Alaya AI采用创新的微数据模型(Tiny Data),在传统大数据的基础上进行优化和迭代,从多个方面提高了深度学习的训练效果:
数据质量优化微数据模型聚焦于高质量的小规模数据集,通过数据清洗、标注优化等手段,提高数据的准确性和一致性。高质量的训练数据可以有效提升模型的泛化能力和鲁棒性,减少噪声数据对模型性能的负面影响。
数据特征浓缩微数据模型采用特征工程和数据浓缩技术,提取数据的关键特征,去除冗余和无关信息。浓缩后的数据集包含更高密度的有效信息,能够加速模型的收敛速度,同时降低计算资源消耗。
样本均衡优化深度学习模型的性能往往受到数据分布不平衡的影响。微数据模型采用智能的数据采样策略,对不同类别的样本进行均衡化处理,确保模型在各个类别上都有足够的训练数据,提高模型的分类准确率。
主动学习策略微数据模型引入主动学习策略,通过模型反馈动态调整数据选择和标注过程。主动学习可以优先选择对模型提升效果最大的样本进行标注,避免低效的重复劳动,提高数据利用效率。
增量学习机制微数据模型支持增量学习,可以在原有模型的基础上,持续添加新的数据进行训练,实现模型性能的迭代优化。增量学习使得模型可以持续学习和进化,适应不断变化的应用场景需求。
迁移学习能力微数据模型具备迁移学习能力,可以将已训练好的模型应用到相似的新任务中,大大减少新任务的数据需求和训练时间。通过知识的迁移和复用,微数据模型可以在小样本场景下取得良好的训练效果。
同时,Alaya AI集成了AI训练与部署工具,支持常用的深度学习框架,使得各种AI模型都能够直接识别并使用,降低了上游模型训练的使用成本。此外,利用零知识证明等密码学算法与访问控制技术,Alaya AI全程保护用户隐私不受侵害。
生态建设
当前Alaya AI支持Arbitrum与opBnB两大主网,支持邮箱注册,手机App已经登录Google Play。
从B端来看,Alaya AI已经与超过十家AI科技公司建立了稳定合作,并且合作数量还在持续上升中。这使得Alaya实现了稳定的现金流变现,可以稳定地向用户提供现金和Token奖励。
从C端来看,Alaya AI当前拥有超过40万注册用户,超过两万日活用户,每日链上交易数超过1500。此外,Alaya构建了去中心化的自治社区,将以公开、透明、民主的方式决定产品的走向。
在未来,Alaya AI有望与DePIN进一步融合,内置于一体化的AI智能硬件产品中(例如,Rabbit R1),从用户的日常交互中获得数据,并且利用设备的闲置算力。此外,通过与去中心化算力平台(例如Akash、Golem)的合作,Alaya AI能够建立一个AI数据+算力的统一市场,使得AI开发者只需专注于算法的优化。在数据的存储方面,Alaya AI可以将完成标注的数据存储与IPFS、Arweave等去中心化存储协议,并同去中心化的AI模型市场(例如,Bittensor)积极展开合作,用去中心化的数据训练去中心化的模型。

代币激励
Alaya AI的代币系统主要分为两部分,一部分用于用户激励,另一部分用于生态激励。
第一部分是AIA token,AIA是Alaya的基本平台激励token,用户完成任务,实现里程碑和参与产品内的其他活动皆可获得AIA token的奖励。AIA token还可以用于用户NFT的升级,活动参与的门槛以及独特成就的获取,这些都可以增加玩家在产品里面的基本产出。AIA token具备基本的产出与消耗场景,且二者相互促进。
第二部分是 AGT token,AGT 是Alaya的治理代币,最大发行量为50亿。AGT用于生态系统开发,高级NFT的升级和参与社区治理等行为。用户必须持有AGT才能参与社区治理,数据审查和发出请求等。
Alaya Ai的双代币模型使得经济激励与治理分离,这样可以避免治理代币的大幅波动影响系统经济激励的稳定性,使整个系统具备更强的可扩展性,更有利于系统长期良性发展。
竞品分析
将现有的去中心化数据标注项目对比列表如下:
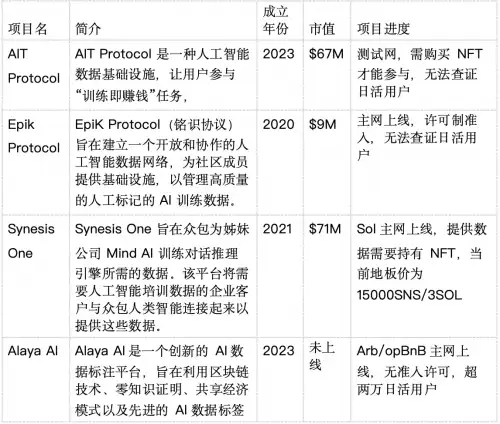

从竞品分析来看,新项目与老项目相比,在代币表现上会更好。同时,有真实用户数据支撑的项目要显著优于缺少用户的项目。Alaya AI作为拥有超过40万注册用户,超过两万日活用户,每日链上交易数超过1500的新兴项目,发币后大概率获得更好的价值支撑。
责任编辑:kj005
文章投诉热线:182 3641 3660 投诉邮箱:7983347 16@qq.com