中华网数码
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。

近日,Soul App AI团队(Soul AI Lab)正式发布开源模型SoulX-LiveAct,这一创新性的实时数字人生成方案通过Neighbor Forcing(同扩散步对齐的自回归条件传播)与ConvKV Memory(KV记忆压缩)两大核心技术,成功推动AR diffusion技术从"能流式"走向"可真正长时稳定地实时流式",为数字人技术的工业化应用开辟了全新路径。
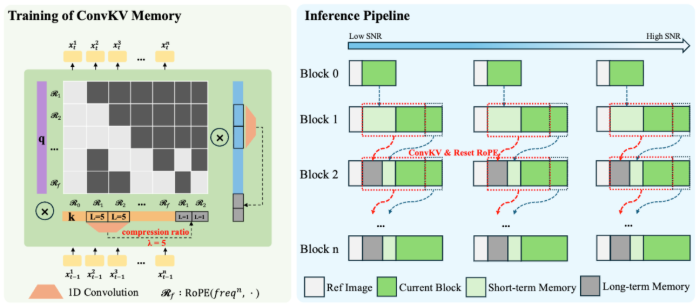
如何让数字人视频在流式实时推理条件下实现小时级甚至无限长度的持续生成,同时保持身份一致、细节稳定、口型精准,一直是行业面临的重大技术挑战。传统的AR diffusion方案往往依赖KV cache来记忆历史信息,但缓存会随着视频长度线性增长,导致视频一长便出现显存爆炸或不得不丢弃历史信息的问题,稳定性随之崩塌。SoulX-LiveAct从"条件传播方式"和"历史记忆管理"两个层面入手,创新性地解决了这一瓶颈,使系统既能承载长时历史信息,又不会因缓存膨胀而拖慢推理速度,从而在机制上具备了小时级甚至更长时长的持续生成能力。
在实际部署层面,SoulX-LiveAct展现出卓越的工程化能力。在512×512分辨率下,该模型仅需2张H100/H200显卡即可达到20FPS的实时流式推理能力,端到端延迟约为0.94秒。更值得关注的是,单帧计算成本降低至27.2 TFLOPs/frame,在追求实时性能的同时显著减轻了算力压力,为线上部署提供了更具现实意义的成本方案。这一突破意味着开发者无需投入巨额硬件成本,即可构建高质量的实时数字人应用。
长视频生成中最容易出现问题的往往不是最初的几分钟,而是随着时间推移逐渐显现的身份漂移、细节丢失等现象。常见的问题包括脸部漂移、发型与衣纹变化、饰品忽隐忽现,甚至口型逐步失配。SoulX-LiveAct通过Neighbor Forcing与ConvKV Memory的协同作用,能够在更长时间窗口内保持身份一致性与关键细节的持续稳定,确保配饰与衣物纹理不会"掉件",口型与音频保持精准同步。
从技术原理来看,SoulX-LiveAct面向小时级实时数字人动画的流式生成,整体采用AR Diffusion(自回归扩散)范式,并围绕"长时一致+恒定显存"构建了两条核心机制。Neighbor Forcing(邻近强制)在自回归链上传播同扩散步下的相邻帧latent作为条件,使上下文与当前预测处于同一噪声语义空间,显著降低了训练与推理中的分布不一致问题。ConvKV Memory(卷积式KV记忆)则将历史attention KV记忆从线性增长的cache改为短期精确与长期压缩的组合模式,近期KV保留高精度窗口以保证局部一致与细节稳定,远期KV通过轻量1D conv按固定压缩比滚动压缩,把历史信息压缩进固定长度表示,从而实现常量显存推理。配合RoPE Reset进行位置编码对齐,有效避免了长序列位置漂移,强化了长时稳定性。
在训练策略上,Soul X-LiveAct的目标不仅是追求视频质量,更是显式对齐流式推理的长时误差传播。Neighbor Forcing对齐训练分布,强制模型在同扩散步语境下接收来自相邻帧的条件latent,减少AR链中跨步噪声空间不一致带来的优化震荡。长时一致性导向的自回归训练构造按chunk方式组织训练样本,显式覆盖连续chunk合成、误差累积与再纠正的过程,让模型在训练期就暴露并学习处理长时漂移问题。Memory-Aware训练引入与推理一致的ConvKV Memory使用方式,让模型学会在被压缩的历史记忆条件下保持身份与细节一致性,避免训练与推理不一致导致的性能下降。
通过在HDTF(面部口型与真实感)与EMTD(包含全身动作)两类基准上的定量对比,SoulX-LiveAct展示了其在口型同步、动画质量与实时效率上的综合领先优势。在HDTF数据集上,该模型取得9.40的Sync-C与6.76的Sync-D,同时在分布相似性指标上达到10.05 FID与69.43 FVD,并在VBench上获得97.6的Temporal Quality与63.0的Image Quality,VBench-2.0的Human Fidelity达到99.9,体现出更稳定的时序质量与更强的人体与身份一致性。在EMTD数据集上,SoulX-LiveAct依然保持最优同步表现,Sync-C达到8.61,Sync-D达到7.29,并在VBench上达到97.3 Temporal Quality与65.7 Image Quality,Human Fidelity达到98.9,充分证明其对全身动作与复杂表情、动作场景的鲁棒性。
依托出色的模型表现,SoulX-LiveAct将在多个应用场景快速落地。在长期在线数字人直播间、AI教育、智慧柜员、知识付费、播客录制、开放世界互动等方向,该模型都展现出广阔的应用前景。特别是在在线开放世界的NPC互动场景中,要求数字人"说得像、动得像、一直像",SoulX-LiveAct在全身数据集EMTD上的同步与质量指标领先,并支持实时流式推理,非常适合在数字空间里实现长时间在线的、具备情绪动作表达的角色交互。
值得一提的是,Soul AI团队正持续推进开源工作。今年,团队已陆续开源了SoulX-FlashTalk与SoulX-FlashHead等多款模型。SoulX-FlashTalk是首个能够实现0.87秒亚秒级超低延时、32fps高帧率,并支持超长视频稳定生成的14B数字人模型;SoulX-FlashHead则是1.3B轻量化模型,可在单张消费级显卡RTX 4090上跑出96FPS的工业级速度。此外,团队还开源了播客语音合成模型SoulX-Podcast、歌声合成模型SoulX-Singer、全双工语音对话控制模块SoulX-Duplug,围绕"实时交互"这一核心领域,在多模态方向不断夯实技术基建,通过工程化部署方案将技术推向可真正工业级应用阶段。
坚持开源方向,Soul不仅完成了自身AI基础设施的持续升级,还通过携手全球开发者,持续拓展"AI+"的新落地场景,共同推动AI应用生态的建设。SoulX-LiveAct的发布,标志着Soul App在实时数字人技术领域迈出了坚实的一步,也为开源社区及行业提供了差异化的实时数字人方案,覆盖各种硬件条件、不同应用落地的开发者实际需求,助力数字人技术走向更加普惠的未来。
责任编辑:kj005
近日,Soul App AI团队(Soul AI Lab)正式发布开源模型SoulX-LiveAct,这一创新性的实时数字人生成方案通过Neighbor For...
2026年3月31日,西瓜创客在成都市教育技术装备管理中心,面向全市各区(市)县及直属(直管)学校的科创骨干教师,成功开展“成都市学生数字素养提升实...
为传承红色基因、弘扬长征精神,切实守护老年群体健康,纪念红军长征胜利90周年系列健康文化活动暨中医药现代化守正创新对抗老慢病科技成果报告会,4月19日在北京人大...
数字文化浪潮蓬勃向前,声音早已超越单纯信息载体的属性,成为传承传统文化、链接当代生活、传递人文温度的重要纽带精品内容出圈,硬核数据彰显实力播放体量与平台评级,是...
4月20日,我爱我家(000560.SZ)发布2025年年度财务报告2025年,我国房地产市场仍延续调整态势,根据中指研究院数据,2025年百城二手住宅价格累计...
当下,全民副业热潮席卷全国,个人技能服务市场迎来爆发式增长美团妙蛙的核心优势,在于背靠美团生态的顶级流量与强大品牌背书智流金海与美团妙蛙,是低风险、高回报的优质...
福州爱尔眼科医院翁景宁教授指出,近视手术本身不存在"反弹"的说法为什么说近视手术不存在"反弹"?要理解这个问题,需要先了解近视手术的原理福州爱尔眼科医院屈光科主...




